ElasticSearch Shards, Heap, 그리고 연휴의 저주
들어가며
Xangle에서 Elastic Search는 검색용 뿐만 아니라 수많은 Node 데이터의 메인 저장소 역할로 갖가지 ETL을 통해 저장 되고 있습니다. 도입 초기 여러 문제 확인과 성능테스트를 통해 날카로울 정도로 다듬었다 생각했는데 데이터의 수(??)에 대한 예측실패로 생긴 heap 메모리 장애, Unassigned shard 장애를 처리 하고 원인을 찾아 해결한 사례를 이야기 해볼까 합니다.
장애징조
Xangle 엔지니어들에게 매번 이야기하는것들이 있다.
“코드만 짜는게 아니라 서비스 운영하는 업무 또한 엔지니어 업무다.”
25년 3월 12일 오후 8시 34분,
ES에서 shard size 에러 알림을 받았다. 총 4대의 DataNode에서 몇몇 Shard Index 크기가 너무 크다는 알림이였다. 모니터링 툴로 확인해보니 몇몇 트렌젝션 indeces Documents 크기가 20TB를 넘어섰고 shard 크기가 개당 1TB를 넘어선것이다. shard의 크기를 줄여야겠다는 생각으로 shard 갯수를 늘렸다.
25년 4월 9일 오후 2시 55분,
Xangle 꽃미남(JWI)께서 ES 장애에 대한 보고를 줬다. ES에서 too many request 429 에러와 함께 1 초당 insert TPS는 약 14000…. 약 9900개가 실패중으로 10번의 insert 중 7번이 실패였다.
얼마전 Collector(Node수집Application)의 성능을 올리는 작업을 했기에. Collector의 ES 데이터 인입을 조절하여 우선 서비스가 동작하게 했다. 데이터가 많아졌지만 그에 따른 DataNode도 늘려주었다. 2년간 문제가 없다가 원인이 뭐지?
25년 5월 2일 오전 10시 24분,
Xangle의 꽃미녀(SMH) 엔지니어께서 다급하게 날 찾아왔다.
“재영님 ES에서 이상현상이 발생중이에요 ES 자체가 뻗기 직전입니다.” 다행히 오전이여서 전문 엔지니어들도 많고 대책을 바로 세우기 시작했다. 저번 처럼 ES에 데이터를 insert 시키는 Collector들을 멈추었다. ES는 재기동 후 동작 해보았다. 서비스들은 정상동작했고, 필수 Collector 외에는 우선 사용하지 않고 필요없는 데이터는 삭제 처리했다…한달 전에는 Collector 인입 문제라고 판단했는데 그게 아니였던가??
이번에는 정확한 원인을 파악할수 있지 않을까 기대했고, 여러 정보들을 모아 시도해보았다.
같이 죽자
ES뿐만 아니라 Xangle의 서비스에 문제가 생기면 나나 Infra 엔지니어 혹은 몇몇 개발자들만 죽어나고 있는것을 발견했다.
오케이 좋아. 같이 죽어보자란 마음으로 Slack에 서버 이상시 모든 개발자들에게 메세지가 가도록 설정했다.
Slack 폭탄이 시작되었고, 적절한 조정을 해놨다. 모든 개발자들이 Slack을 받게 되자 변태 처럼 기뻐했다.
원인 찾기
25년 5월 2일 오후2시,
Xangle의 핵심 엔지니어들을 불러 모았다. ES의 이상 현상에 대한 원인분석이 시작되었다.
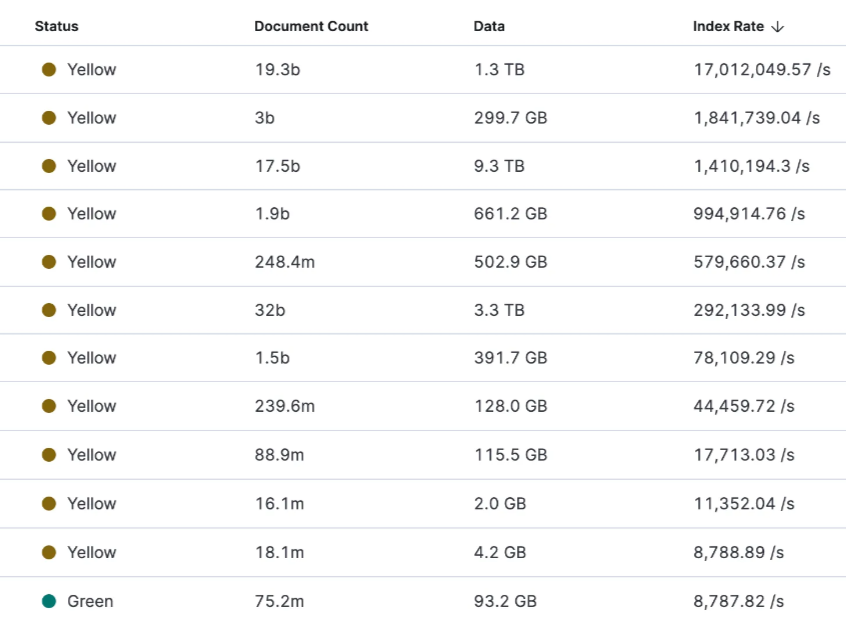
indices의 상태가 거의 대부분이 Yellow이다.
모니터링 정보를 토대로 데이터의 크기가 문제라고 생각되었다. Document Count가 정상적인 수치가 없었다. Data 크기도 말이 안된다. Index Rate도 말이 안될정도로 높았다.
데이터의 shard 크기나 전체 용량 대비 60% 사용중이였다. 데이터 노드의 추가라면 분산 처리 되어 해결될수 있는가가 요건이였다.
공교롭게 내일부터 연휴로 인해 대응적인 면에서 좋지 않다고 판단하여
연휴가 끝나면 3가지를 트라이 해보기로 했다.
- DataNode를 1대 더 늘려 병렬 연산 처리 하도록 처리
- Shard 크기를 더 줄여보기
- ReIndexing 처리 하기
Judgment Day
25년 5월 3일 오전 9시 48분 (5월 연휴의 시작날이였다..),
Xangle의 모든 ETL이 마비되었다. ES가 insert 먹통이 되버린것이다. select도 동작하지 않았다.
ES 자체에서 서킷브레이커가 발동 되어 무한 루프로 동작을 제어 중이였다.

더 문제는 kibana도 동작하지 않았다. 특단의 조치가 필요한 상황이였다.
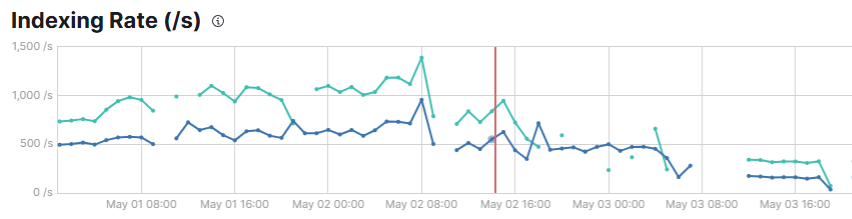
latency가 늘어나 수많은 shard에 데드락이 걸리니
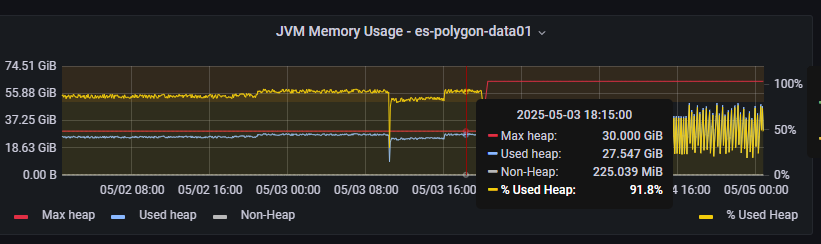
heap에서 저장해야 할것이 많아지고 가비지 컬렉션에서 STW 횟수가 많아졌다. 데이터가 말도 안되게 많아야 발생하는 문제로 개발장비에서나 2년전 초기 성능테스트에서는 잡지 못했던 이슈였다.
2년전 성능테스트에서는 약 100억건(5TB)의 row데이터를 indices 20개정도(shard 5개)로 로 처리했을땐 문제가 없었지만, 현재는 1000억건(60TB) row데이터에 indices의 수는 400개로 늘어났다. shard 크기는 개당 20개였다..
indices(400) x shard(20) = 총 8000개 shard…….;;;;
문제해결
수 시간의 회의 및 조사 분석을 통해 꼬리가 잡히는 순간이였다.
깨진 shard를 날려 먹으면 최악의 상황이 발생하기에 우선 깨져있는 shard 부터 정리하는게 우선이였다.
5월3일 오후2시
“reindexing 부터 합시다.”
모든게 순조로와 보였다. 그러나.. ES는 우리를 가만 두지 않았다.
Reindexing을 시작한지 약 8시간 뒤
또 문제가 발생했다. heap 자체가 reindexing을 할 정도로 여유공간이 남아있질 않았다.
ElasticSearch에서는 메모리를 32GB 이상 올리지 말라는 권장사항이 있기에 Xangle도 32GB로 DataNode를 셋팅했고 총 6대니 메모리 총량은 192GB였으나 heap사용률이 99%이상 사용시 reindexing을 중단해버렸다.ㅠ원인은 알고 있지만 리스크가 큰 작업을 해야되는 상황이였다.
DataNode의 메모리를 64GB로 우선 올려 Reindexing이 끝나면 재 구성하기로 결정했다. Reindexing 처리는 정상적으로 처리되었으며 heap 메모리 또한 안정적으로 구동되었다. 완료될때까지 그 외의 작업을 시작했다. shard 크기를 기존 20개에서 50개까지 늘렸고, 용량이 큰 indices의 rollover 처리를 해두어
데이터 분산 처리 작업을 하였다.
5월5일 새벽 0시 2분
약 34시간동안의 Reindexing 작업이 끝나고,
Rollover indices를 정의하여 작업 하였다.
- 목록
- transaction
- testnet-transaction
- all-transaction-list
- user-transaction-list
- testnet-internal-transaction
하나의 index를 여러 shard로 분할 하기보다 index를 분리하는게 낫다는 판단을 하였고, 병렬처리의 강점은 있지만 단일 index 용량이 수TB가 넘는 상태에서의 병렬처리는 독약이였다. ElasticSearch Documents에서도 Index의 shard가 단일 기준 50GB가 넘는다면 분리하는게 좋다는 의견을 참고 하였다.
제일 걱정했던 alias 문제도 쉽게 처리 되어 Rollover 작업 자체는 수시간 정도밖에 걸리지 않았다.
5월6일 오전 10시 28분
모든 작업을 마치고 조심스레 재시동 하였다. ElasticSearch는 4일간 고생한 Xangle 엔지니어들의 고생을 알아주듯 모든 상태가 all Clear였다.
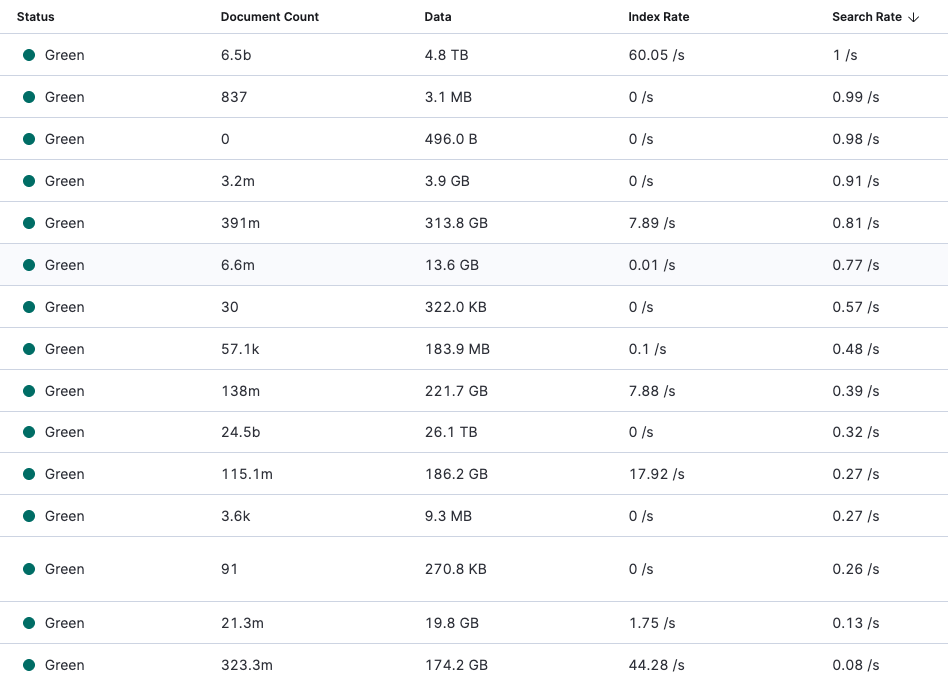
정상화된 indices 및 index rate & search rate
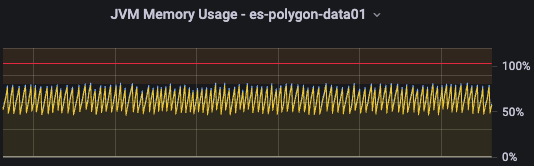
정상화 된 JVM 메모리
마치며
ElasticSearch는 강력한 도구이지만, 방대한 데이터를 다루는 상황에서는 그만큼 섬세한 운영과 지속적인 구조 개선이 필요하다는 사실을 다시금 절감한 사건이었다. 이번 장애는 단순한 트래픽 폭주나 순간적인 이슈가 아니라, 2년 넘게 안정적으로 운영되어 오던 시스템에 “데이터의 성장”이라는 조용하지만 거대한 파도가 몰아친 결과였다.
“잘 만든 시스템은 알아차리지 못하게 잘 돌아가는 시스템”이라는 말처럼, 그동안 문제없이 흘러가던 데이터 흐름 속에 숨어 있던 위험 신호들을 더 일찍 감지하지 못한 점도 반성하게 되었고, 동시에 이 경험을 통해 Xangle의 ElasticSearch 운영 노하우는 더욱 견고해졌다.
이 사건은 단순한 장애 해결을 넘어, 개발자들이 서비스 전체의 생명주기를 함께 책임져야 한다는 메시지를 다시 한번 각인시켜 주었다. 그리고 무엇보다도, 위기 속에서도 끝까지 함께 고민하고, 고생하며, 결국엔 문제를 해결해낸 동료들의 헌신이 있었기에 가능했다.
ES의 정상화를 보며 느꼈다. 시스템은 사람의 손으로 망가지기도 하지만, 사람의 힘으로 얼마든지 다시 살릴 수 있다는 것을..
마지막으로 해당 이슈에 대해 3일 밤낮 고생해주신 조상욱,조원익,이다빈,황윤하 개발자께 감사와 경의를 표한다.